 If you’ve ever attended an AWS webinar or event (re:Invent is a total blast — you gotta go), you’ll hear lots of talk about how the AWS cloud “eliminates heavy lifting.” What the AWS folks mean with that catchphrase is that in AWS services, an important design point is eliminating configuration and management dross (which, over time, leads to “configuration cruft” and other undesirable nastiness 🙂 ).
If you’ve ever attended an AWS webinar or event (re:Invent is a total blast — you gotta go), you’ll hear lots of talk about how the AWS cloud “eliminates heavy lifting.” What the AWS folks mean with that catchphrase is that in AWS services, an important design point is eliminating configuration and management dross (which, over time, leads to “configuration cruft” and other undesirable nastiness 🙂 ).
Architects and developers have grown so accustomed to fighting their way through the need to specify this and configure that to get any real work done that many have long since grown inured to the hopelessness of it. When you first start using AWS, it feels like someone else is breaking the rocks for you. Freed of the drudgery, it’s no surprise that people develop a gushing love for AWS that can be a little embarrassing to people who haven’t used the cloud.
Nothing, and I mean nothing, in my experience is so fraught with contingencies and complex infrastructure as relational database backup. A recent re-acquaintance with AWS Relational Database Service (RDS) and its recovery capabilities has (once again) driven home the impact of someone else doing the heavy lifting.
In RDS, backup and recovery is a simple matter of understanding three basic concepts:
- A backup window is when RDS takes a daily snapshot of the data (and, thank goodness, the instance itself). You specify when you want this to happen
- The retention period describes how long you want the instance/volume snapshot to be retained. This can be up to 35 days
- The last restorable time. This is, duh, the most recent time from which you can restore (to a new instance) the database.
It’s just so simple — you don’t have to worry about backup infrastructure at all. (Keep the last fifteen minutes in a transaction log, get incremental backups every hour, full nightlies daily, then roll all the dailies over once a week. Monitor the backups. Debug backup crashes. Make sure there’s enough space on the volumes…and on and on and on!)
Still, an important question for RDS restore is, “How frequently is RDS setting the LRT?” Or, in plainer English, “How much data (time) would I lose if the RDS instance dies?” (We’re only considering RDS instances deployed in a single availability zone, as you would do for a low-end application like WordPress. If you use multi-AZ deployment, you may never need to restore an RDS instance.)
Digging around in the AWS doc for the answer to this question, I found that LRT is “typically within five minutes of the current time.” Since the standard DBMS RPO is 15 minutes, a five minute interval, if true, would mean that the last mega rock had been broken into little rocklets. But I wanted to see for myself that RDS was really doing this — after all, there must be millions of RDS databases and to scale the cloud to make them all restorable within the last five minutes would be an astonishing achievement.
As you can see in the screenshot below, a simple PowerShell script that ran for 20 minutes demonstrates that AWS is, indeed, making that very tight RPO possible. My little test instance was off only twice, by an insignificant minute or so.
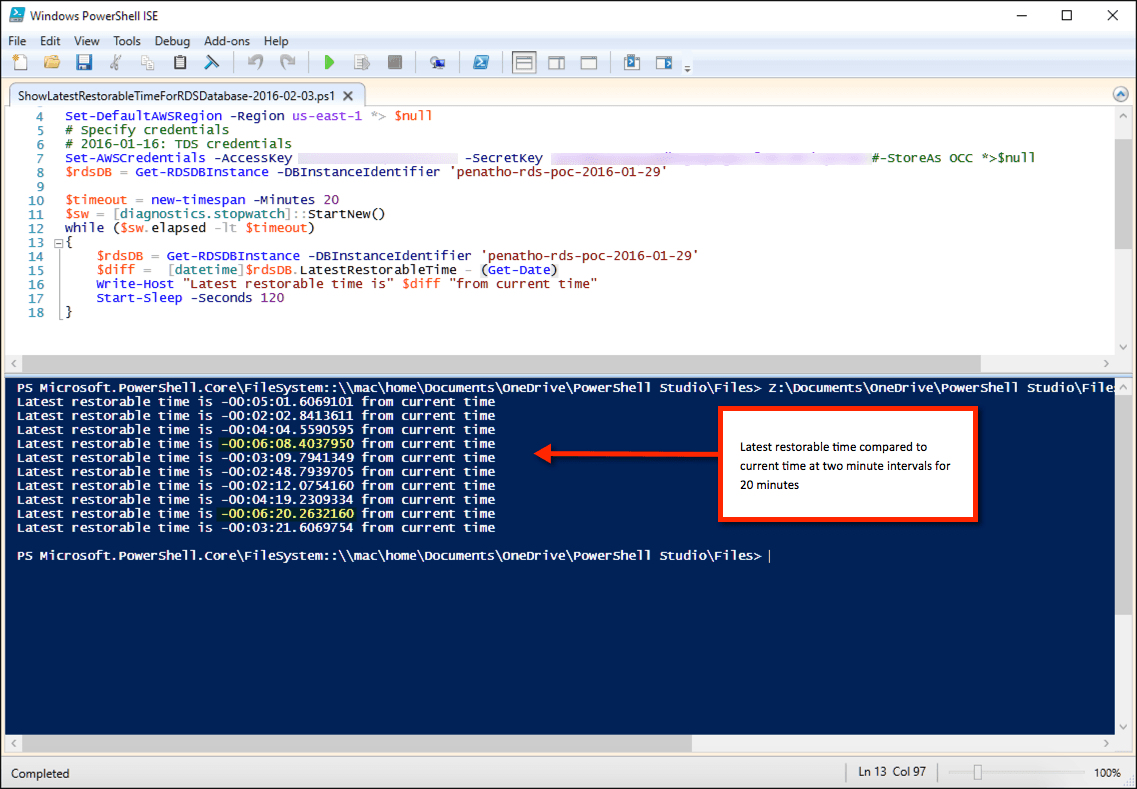
If you’d like to try this on your own RDS instance, here’s the PowerShell script. Just add your credentials, the RDS instance tag and change the times if you want to test longer/shorter periods.
Import-Module AWSPowerShell
Set-DefaultAWSRegion -Region SPECIFY-REGION *>$null
Set-AWSCredentials -AccessKey ACCESS-KEY -SecretKey SECRET-KEY *>$null
$timeout = new-timespan -Minutes 20
$sw = [diagnostics.stopwatch]::StartNew()
while ($sw.elapsed -lt $timeout)
{
$rdsDB = Get-RDSDBInstance -DBInstanceIdentifier 'RDS-INSTANCE-TAG'
$diff = [datetime]$rdsDB.LatestRestorableTime - (Get-Date)
Write-Host "Latest restorable time is" $diff "from current time"
Start-Sleep -Seconds 120
}
This is a perfect example of AWS simplifying and improving database backup. All you have to do is change your thinking about how database backup should work. Once you do, you too can begin to feel that enveloping love of AWS.
Leave a Reply